Category: Life like a box of chocolate
TCP HTTP TLS
TCP 传输层协议
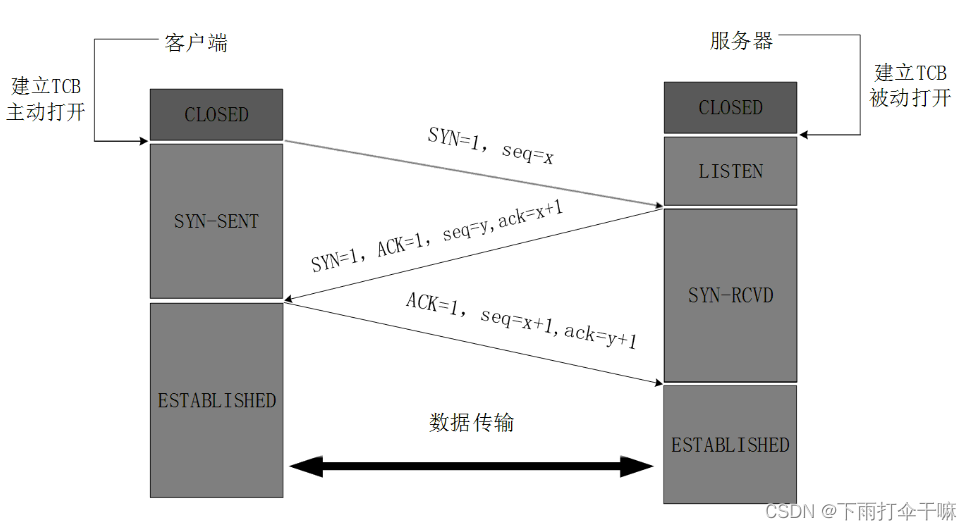
TCP 三次握手: x , y 为随机生成的序号
- 客A主动发起一个连接请求,即 SYN=1,同时带上一个随机生成的序号×,即 seq=x。
- 服B在收到请求后进行响应,也将 SYN设为1,同时确认客A的请求有效,即 ACK=1,ack=x+1,将自己随机生成的序号y也传给客A, 即 seq=y.
- 客A在收到服B的响应后作出反应,确认有效即 ACK=1,ack=y+1,seq=x+1(因为客A中间没有再向服B发送数据所以x没有改变)。
- 客A和服B进行数据传输。
为什么要三次握手: 因为三次握手是保证client和server端均让对方知道自己具备发送和接收能力的最小次数。
为什么每次还要发送SYN或者ACK?
为了保证每一次的握手都是对上一次握手的应答,每次握手都会带一个标识 seq,后续的 ack 都会对这个 seq 进行+1来进行确认。也就是保证每次的握手双方都是同一个对象,防止中途被替换了。
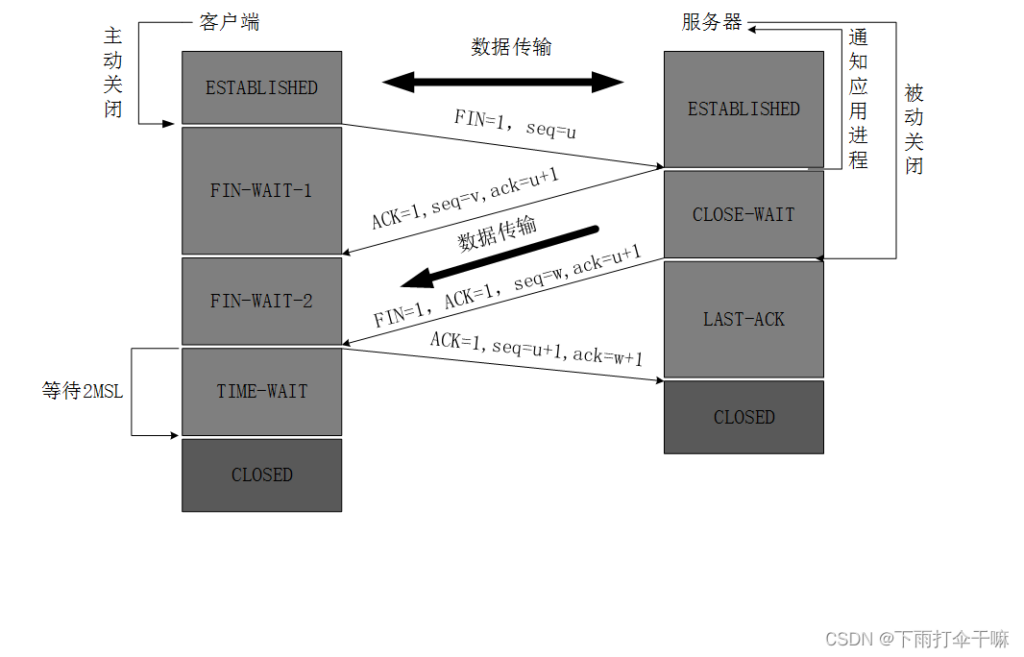
四次挥手:
- 客A主动发起关闭,即 FIN=1,同时带上随机生成的随机数u,即 seq=u。
- 服B收到请求后进行响应,确认请求有效,即ACK=1,ack=u+1,同时带上自己生成的随机数V,即 seq=V。此时服B并没有完全关闭,而是处于半关闭的状态,仍旧能够向客A发生未发送完的数据。
- 当服B把需要发送的数据发送完后就进行剩下的关闭请求操作,即 FIN=1,ACK=1,ack=u+1,因为处于半关闭状态的服B可能对客A发送了数据,所以序号不确定,即 seq=W。
- 客A收到服B的信息后作出响应,即 ACK=1,ack=w+1,因为中间客A没有再进行数据传输所以u不变,即 seq=u+1。
- 客A等待一段时间后完成挥手。
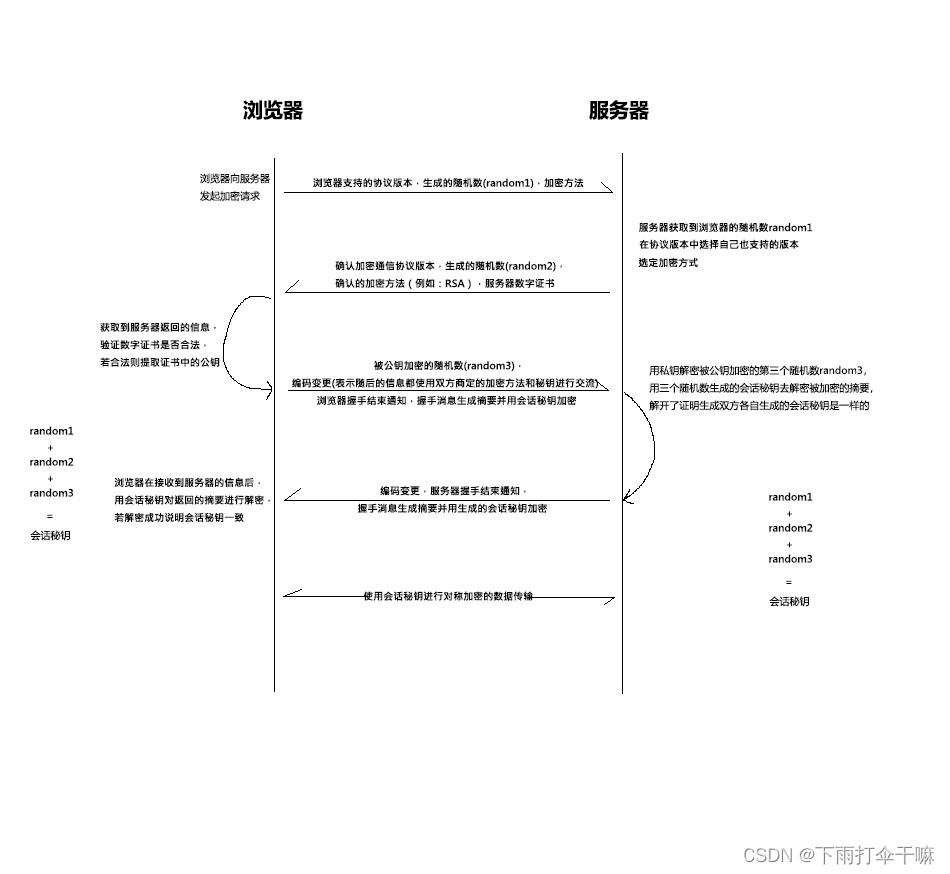
HTTPS 连接建立
首先TCP 三次握手建立连接 然后 ssl/tls 建立连接
- 浏览器向服务器发起加密请求,同时传送浏览器支持的协议版本,浏览器随机生成的随机数random1,以及支持的加密方法。
- 服务器收到请求后在获取到的协议版本中选择自己也支持的版本,例如:TLS1.2,选定同样支持的加密方式,例如:RSA,连同目己生成随机数random2和服务器数字证书一起传给浏览器。
- 浏览器收到数字证书后并确认证书合法,使用证书中的公钥加密浏览器随机生成的随机数random3。此时浏览器已经有三个随机数: random1,random2和random3,三个随机数生成此次的会话秘钥。将之前握手的消息生成摘要,然后用生成的会话秘钥加密,然后将被公钥加密的随机数random3,被会话秘钥加密的摘要发送给服务器,同时进行编码变更,告知浏览器端的握手过程已经结束,随后的信息交流都使用各自生成的会话秘钥进行加密交流。
- 服务器收到消息后,使用私钥进行random3的解密,获取第三个随机数,然后也生成此次的会话秘钥,使用会话秘钥对加密的摘要信息进行解密,证明双方生成的会话秘钥是一致的。再将之前的握手信息也生成摘要,使用自己生成的会话秘钥进行加密,将加密的摘要发送给浏览器,同时编码变更以及完成服务器端的握手过程。
- 浏览器接收到加密的摘要后,使用会话秘钥进行解密,确保双方生成的会话秘钥是一致的。
- 接下来就是使用各自生成的会话秘钥进行对称加密的数据传输
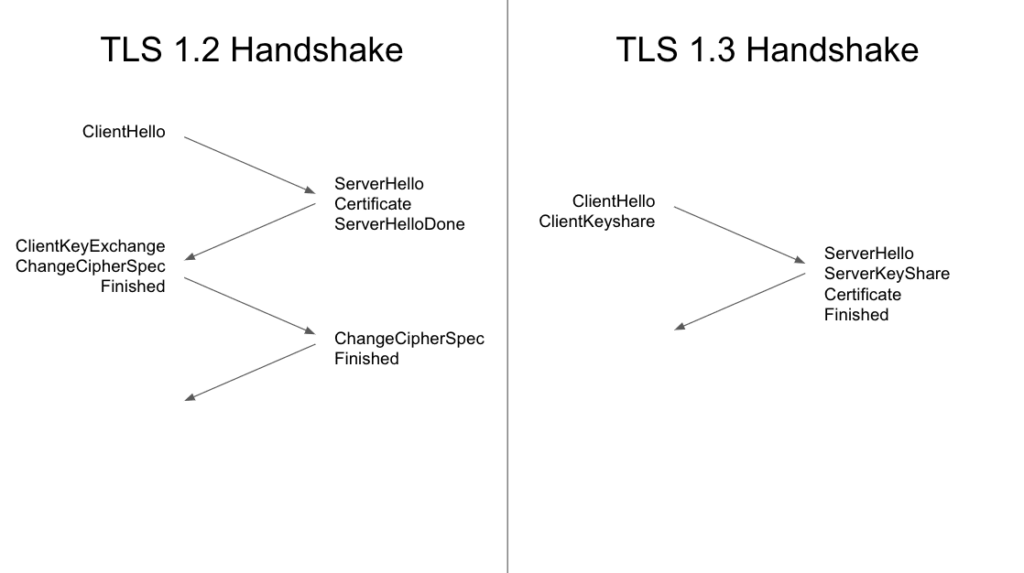
TLS 1.3
TLS 1.3 是最新版传输层安全协议 (TLS),即 HTTPS 使用的加密协议。与 TLS 1.2 相比,TLS 1.3 可提供更好的隐私保护和性能。
TLS 1.3 将 TLS 握手从两次往返缩短为一次。对于使用 HTTP/1 或 HTTP/2 的连接,将 TLS 握手时间缩短为一次往返,可有效将连接设置时间缩短 33%。
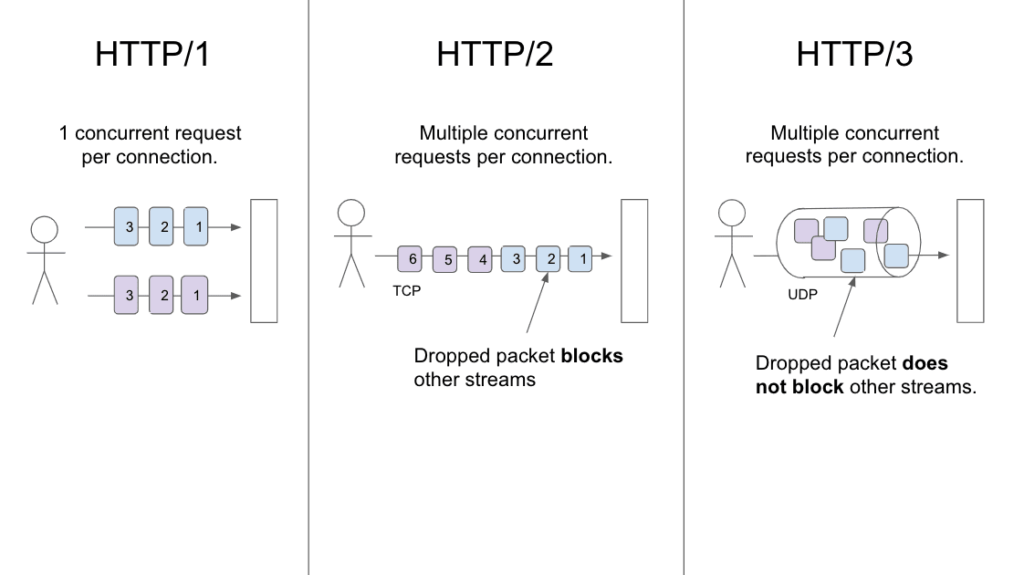
HTTP/2 和 HTTP/3
与 HTTP/1 相比,HTTP/2 和 HTTP/3 都提供性能优势。在两者中,HTTP/3 具有更大的潜在性能优势。HTTP/3 尚未完全标准化,但一旦发生这种情况,就会受到广泛支持。
HTTP/2
HTTP/3
HTTP/3 是 HTTP/2 的继任者。截至 2020 年 9 月,所有主流浏览器均提供对 HTTP/3 的实验性支持,部分 CDN 支持 HTTP/3。性能是 HTTP/3 优于 HTTP/2 的主要优势。具体来说,HTTP/3 消除了连接级别的队头屏蔽问题,缩短了连接设置时间。
消除队头屏蔽
HTTP/2 引入了多路复用功能,该功能允许使用单个连接同时传输多个数据流。然而,使用 HTTP/2 时,一个丢弃的数据包会阻止连接上的所有数据流(这种现象称为队头阻塞)。使用 HTTP/3 时,丢弃的数据包仅阻塞单个数据流。这一改进主要是 HTTP/3 使用 UDP(HTTP/3 通过 QUIC 使用 UDP)而非 TCP 的结果。这使得 HTTP/3 对通过拥塞或有损网络进行的数据传输尤其有用。
SSO
什么是单点登录
单点登录(SingleSignOn,SSO),就是通过用户的一次性鉴别登录。当用户在身份认证服务器上登录一次以后,即可获得访问单点登录系统中其他关联系统和应用软件的权限,同时这种实现是不需要管理员对用户的登录状态或其他信息进行修改的
什么是CAS
简单来说,SSO仅仅是一种架构设计思想,而CAS 则是实现 SSO 的一种手段。两者是抽象与具体的关系。当然,除了 CAS 之外,实现 SSO 还有其他手段,比如简单的 cookie。
CAS (Central Authentication Service)是耶鲁 Yale 大学发起的一个java开源项目,旨在为 Web应用系统提供一种可靠的 单点登录 解决方案(Web SSO),CAS 具有以下特点:
- 开源的企业级单点登录解决方案;
- CAS Server 为需要独立部署的Web 应用,一个独立的Web应用程序(cas.war)。;
- CAS Client 支持非常多的客户端(指单点登录系统中的各个 Web 应用),包括 Java,.Net, PHP, Perl,等
单点登录的演进
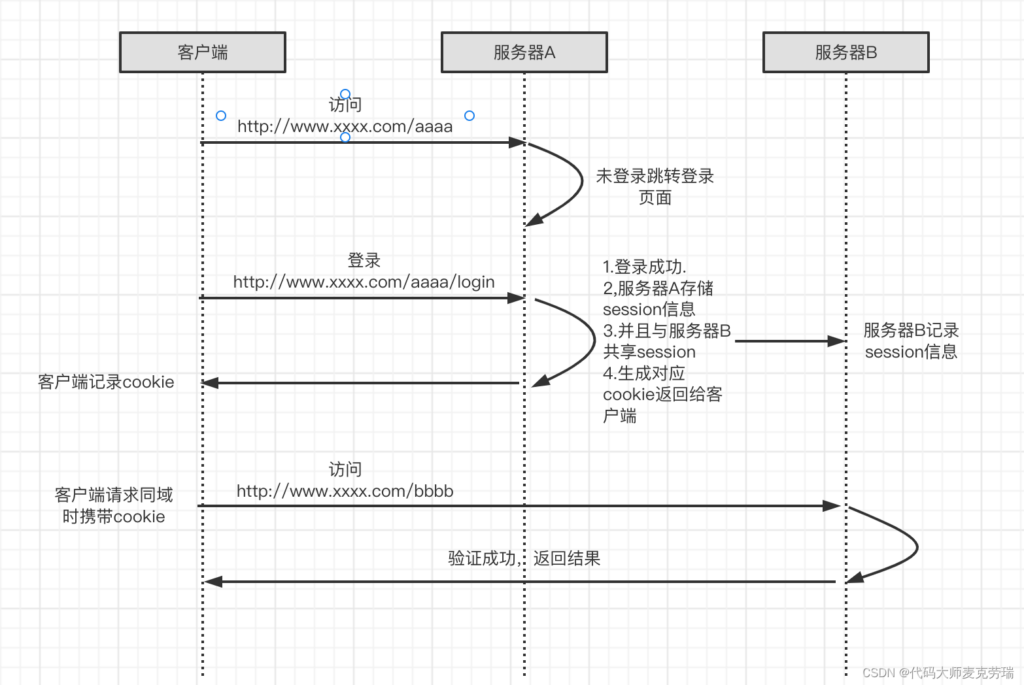
同域
同域,一般情况下是最简单的一种,一般使用cookie、session的方式就可以解决,这里我们强调一下cookie是不可以跨域的
同父域
同父域 SSO 是同域 SSO 的简单升级,唯一的不同在于,服务器在返回cookie的时候,要把cookie的domain设置为其父域。
举个栗子,http://ww.xxxx.aaa.com和http://ww.xxxx.bbb.com。他们的父域名是http://www.xxxx.com,因此将cookie的domain设置为http://www.xxxx.com即可。
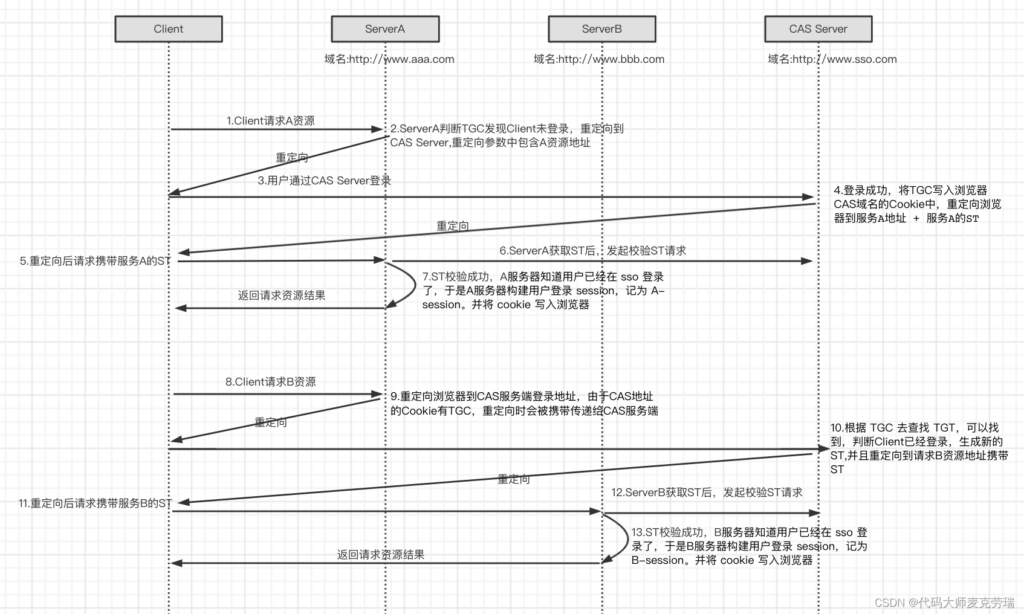
3. 跨域CAS
CAS术语
- Client:用户。
- Server:中心服务器,也是 SSO 中负责单点登录的服务器。
- Service:需要使用单点登录的各个服务,相当于上文中的产品 a/b。
接口:
- /login:登录接口,用于登录到中心服务器。
- /logout:登出接口,用于从中心服务器登出。
- /validate:用于验证用户是否登录中心服务器。
- /serviceValidate:用于让各个 service 验证用户是否登录中心服务器。
票据
TGT: Ticket Grangting Ticket
TGT是CAS为用户签发的登录票据,拥有了TGT,用户就可以证明自己在 CAS 成功登录过。TGT 封装了 Cookie 值以及此 Cookie 值对应的用户信息。当 HTTP 请求到来时,CAS 以此 Cookie 值 (TGC)为key 查询缓存中有无 TGT,如果有的话,则相信用户已登录过。
TGC: Ticket Granting Cookie
CAS Server 生成TGT放入自己的 Session 中,而 TGC 就是这个 Session 的唯一标识(Sessionld),以Cookie 形式放到浏览器端,是 CAS Server 用来明确用户身份的凭证。
ST: Service Ticket
ST是CAS 为用户签发的访问某一service 的票据。用户访问 service 时,service 发现用户没有ST,则要求用户去 CAS获取 ST。用户向CAS 发出获取 ST 的请求,CAS 发现用户有 TGT,则签发一个ST,返回给用户。用户拿着 ST 去访问 service,service 拿ST 去CAS 验证,验证通过后,允许用户访问资源。
k8s 介绍
node:假如一个k8s集群三台机器:A、B、C,ABC称为节点。Node节点的IP地址,即物理机(宿主机)的网卡地址;
pod:k8s的中心思想是每个容器只安装1个进程,多个或1个容器属于一个pod。然后这个pod下的容器可以通过volume的方式共享磁盘。也就是说,应该把整个pod看作虚拟机,然后每个容器相当于运行的虚拟机的进程。
deployment:是最常用的 k8S 工作负载控制器(Workload Controllers),是 k8s 的一个抽象概念,用于更高级层次对象,部署和管理 Pod。主要功能:应用部署、应用升级、应用实例扩容、缩容、发布、失败回滚、应用下线。
k8s集群有3种IP地址,分别如下:
Node IP ,Node节点的IP地址,即物理机(宿主机)的网卡地址;从集群的VPC网络为节点分配IP地址
Pod IP,Pod的IP地址,docker0网桥分配的地址, 是虚拟的二层网络。可以实现不同node中pod之间的通信。通过–pod-cidr指定pod的可分配IP地址段。
Cluster IP,也可叫Service IP,由k8s管理和分配,来源于cluster ip地址池。无法被ping,因为没有“实体网络对象”。只能结合service port组成具体的通信端口。从集群的VPC网络为每项服务分配IP地址。
Node节点主机查看IP地址
# ifconfig 查看
eth0: flags=4163<xxxx> mtu 1500
inet 10.232.35.45 netmask 255.255.255.0 broadcast 10.232.35.255
k8s master通过kubectl describe node k8s-master命令查看Node IP地址
# kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP XXXX
K8s-master Ready master 23d v1.19.0 10.232.35.45
# kubectl describe node k8s-master
name: k8s-master
....
Addresses:
InternalIp: 10.232.35.45
Hostname: k8s-master
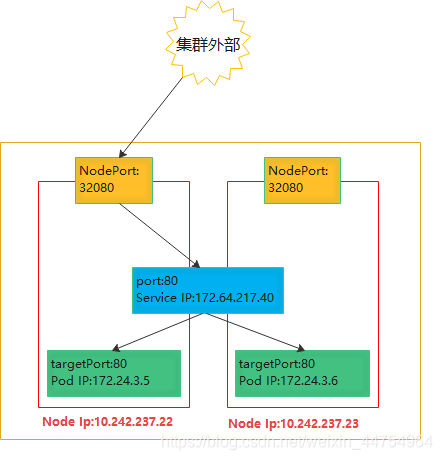
当Service的type为NodePort时,Service将Pod端口映射到Node端口,集群外部可以通过NodeIP:NodePort访问Service里的Pod
apiVersion: v1
kind: service
metadata:
name: ingress-nginx
spec:
ports:
- port: 80
protocal: TCP
targetPort: 80
nodePort: 32080
type: NodePort
可通过NodeIP:NodePort(10.234.115.22:32080,10.234.15.23:32080)访问:
# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP
K8s-node1 Ready master 23d v1.19.0 10.234.115.22
K8s-master Ready master 23d v1.19.0 10.234.15.23
# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx NodePort 172.63.23.20 <none> 80:32080/TCP, 10d
# telnet 10.234.115.22 32080
Connected to 10.234.115.22
2. Pod IP
- 同Service下的pod可以直接根据PodIP相互通信
- 不同Service下的pod在集群间pod通信要借助于 cluster ip
- pod和集群外通信,要借助于node ip
3. Cluster IP
Cluster IP是一个虚拟的IP,实际是一个伪造的IP网络。Service可以为一组具有相同功能的容器应用提供一个统一的入口地址, 并且将请求负载分发到后端的各个容器应用上,可以将后端的多个容器看做一个集群,Service是集群的入口。所以Service IP也叫做Cluster IP。
- Cluster IP仅仅作用于kubernetes Service这个对象,并由Kubernetes管理和分配IP地址(来源于Cluster IP地址池)
- Cluster IP无法被ping,因为没有一个“实体网络对象”来响应
- Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备TCP/IP通信的基础,并且它们属于Kubernetes集群这样一个封闭的空间,集群之外的节点如果要访问这个通信端口,则需要做一些额外的工作。
# kubectl get service -n ingress-nginx -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default-http-backend NodePort 172.63.223.10 <none> 80/TCP, 10d
ingress-nginx NodePort 172.63.23.20 <none> 80:32080/TCP, 10d
4. 集群DNS
完成从服务名到clusterIP的解析。
DNS服务经历从skyDNS到kubeDNS再到coreDNS的过程。k8s通过Add-On增值包的方式引入DNS系统,把服务名作为dns域名。程序就可以直接使用服务名来建立通信连接。
5. 3种IP 通信
集群外部访问Pod,先到Node网络(Node IP)的端口NodePort,再转到Service网络(Cluster IP)的port,最后代理给Pod网络(Pod IP)的targetPort。详细流程如下
6 容器中的数据到外网
从容器发出的数据包先到达br0,然后交给host机器的协议栈,由于目的IP是外网,且host主机开启了IP forward功能,数据包会通过eth0发出。因容器分配的网段都不在物理网络网段内,所以一般发出去之前先做NAT转换。(可以用iptables进行转换)
当涉及转发的目的IP地址是其他机器时,需要确保启用ip forward功能,即把linux当作交换机
可视化3d文件查询系统
pxe
1. 本地网卡ROM中包含有PXE客户端软件。网卡启动时会发出DHCP请求,从PXE服务器端获得动态IP地址、网关及TFTP服务器信息后,
它会自动下载一个用于引导操作系统的启动软件包到本地内存,
再通过此软件加载操作系统启动文件,从而开始操作系统的安装工作。
1.1 使用 DHCP 服务器指定preseed.cfg
2. kickstart与preseed简介
kickstart是Red Hat公司针对自动安装Red Hat、Fedora与CentOS这3种同一体系的操作系统而制定的问答规范
kickstart配置文件通过命令行工具system-config-kickstart生成
preseed则是Debian/Ubuntu操作系统自动安装的问答规范
3. PXE服务器的准备
我们需要将CentOS、Ubuntu或Windows等操作系统安装光盘中的文件复制到PXE服务器中,然后当客户机通过PXE技术与服务器成功建立连接后,就可以自动引导操作系统的安装了。
如果我们选择Ubuntu作为PXE服务器的操作系统,那么它不仅可以支持自身的安装,也可以很好地支持CentOS的安装
4. Ubuntu操作系统的基本安装与更新
4.1 安装与配置DHCP、TFTP服务
apt-get install dnsmasq tftpd-hpa
配置TFTP服务时,只需要创建TFTP服务的根目录,这里我们指定/var/tftproot为根目录
接着配置dnsmasq的DHCP服务,其配置文件/etc/dnsmasq.conf的信息如下所示:
bogus-priv
filterwin2k
interface=eth0
domain=nova.com
dhcp-range=13.0.0.100,13.0.0.150,12h
dhcp-option=3,13.1.1.1
dhcp-option=6,61.139.2.69
dhcp-option=121,13.0.0.0/8
dhcp-boot=/var/tftproot/pxelinux.0
enable-tftp
tftp-root=/var/tftproot
dhcp-authoritative13.0.0.100~13.0.0.150为客户端通过DHCP获得的IP地址范围。
13.1.1.1是互联网的网关
61.139.2.69 是域名服务器
网络掩码是 8,netmask=255.0.0.0
PXE客户端获得IP地址后,使用TFTP下载/var/tftproot/pxelinux.0文件作为PXE的启动文件
4.2 HTTP 服务的作用与安装
当客户端获得IP地址并成功引导了pxelinux.0文件后,需要进一步下载PXE上需要安装的操作系统文件
我们选择apache2作为HTTP的服务软件
apache2为preseed机制提供的支持会比Nginx更好
apt-get install apache2
4.3 kickstart与preseed配置文件的生成
kickstart配置文件可以使用命令行工具system-config-kickstart或在CentOS下使用图形界面生成,而preseed配置文件只能手动完成
5. 复制Ubuntu操作系统全目录、内核与启动镜像文件
5.1 复制Ubuntu操作系统全目录、内核与启动镜像文件
5.1.1 复制工作主要是将PXE启动文件与操作系统文件分别放入/var/tftproot和/var/www/ubuntu目录中。
前面我们将Ubuntu操作系统下载到服务器的目录中,然后我们准备将其挂载至/mnt目录,相关命令如下:
mount ubuntu-12.04-server-amd64.iso /mnt -o loop
接着复制PXE启动文件及操作系统文件,相关命令如下:
```cp -r /mnt/install/netboot/* /var/tftproot
mkdir -p /var/www/ubuntu
cp -a /mnt/* /var/www/ubuntu```这里需要说明的是,Ubuntu操作系统的PXE启动文件位于ISO镜像的/install/netboot目录中,包含以下内容:
PXE启动所需要的pxelinux.0
pxelinux.cfg目录 :它下面有default 文件,用于指示客户PXE启动后的进一步动作,比如选择哪一个镜像文件菜单
default文件:它实际指向ubuntu-install/amd64/boot-screens/syslinux.cfg
ubuntu-install/amd64目录:这个目录下有initrd.gz与Linux内核这两个文件
5.2 复制CentOS操作系统全目录、内核与启动镜像文件
5.2.1 将CentOS 复制到 PXE操作系统
将整个CentOS文件复制到/var/www/CentOS目录下,相关命令如下:
mount CentOS-6.2-x86_64-bin-DVD1.iso /mnt -o loop
mkdir - p /var/www/CentOS
cp -rf /mnt/* /var/www/CentOS```
将CentOS的内核及启动镜像文件复制到/var/tftproot/CentOS目录下,相关命令如下:
```bash
mkdir -p /var/tftproot/CentOS
cp /mnt/images/pxeboot/initrd.img /var/tftproot/CentOS
cp /mnt/images/pxeboot/vmlinuz /var/tftproot/CentOSCentOS的第二张光盘也应装入PXE操作系统中,这样在安装图形桌面时文件才齐全。具体方法是将第二张光盘中Packages中的rpm包复制到Packages
```bash
mount /home/romi/ISO/CentOS-6.2-x86_64-bin-DVD2.iso /mnt -o loop
cp -rf /mnt/Packages/* /var/www/CentOS/Packages
```-
创建PXE客户端导示文件
6.1为了使PXE客户端启动时能够选择安装CentOS还是Ubuntu,需要准备一下引导菜单文件/var/tftproot/boot.msg
如下### START INSTALLING ###### Choose installation type(0/1/2),the DEFAULT is 100: 0 ubuntu basic: ubuntu install through ks.cfg 1 ubuntu comput node: Ubuntu-12.04-LTS-amd64-No RAID install,preseed …… 6 CentOS-6.2-64-No-RAID-Basic …… 10 CentOS-6.2-64-No-RAID-minidesktop-virtualization-for testing0: ubuntu basic:通过kickstart 安装最基本的Ubuntu,使用的是美国软件源,安装速度基本无法接受。
1: ubuntu compute node:通过Ubuntu 特有的preseed机制进行安装,适合于OpenStack的计算节点。
6: 用于安装基本的CentOS无图形界面。
10: 用于安装包含最小图形界面环境、虚拟化运行与管理工具软件包的CentOS。
6.2 选择安装配置文件
当客户选择了安装相关操作系统所代表的数字后,就将由/var/tftproot/pxelinux.cfg/default文件进一步指定使用的相关配置文件
比如当客户选择0时,系统就通过HTTP服务将/var/www/cfg/ ubuntu-ks-noraid.cfg文件回应给客户端,
代码段 中的ks与preseed语句用于给出客户端取得的安装配置文件的URL地址。cfg文件实际存放在服务器的/var/www/cfg/目录下
docker 里 修改 mysql 8 对外端口
mysql8 docker 容器修改端口 需要到容器里 /etc/mysql/my.cnf 修改或添加端口号, 建议从容器里复制出来修改
1 先复制到host
sudo docker cp wordpress_db_1:/etc/mysql/my.cnf ./ #从容器复制到host2 编辑 my.cnf 修改或添加端口号 如port:3307
3 放回容器
sudo docker cp ./my.cnf wordpress_db_1:/etc/mysql/ #放回容器4 然后重启 docker restart 容器名
修改后的端口和暴露的端口一致就可以连接成功, 如 – port 3307:3307
vue 拖拽滚动
Vue实现简单的鼠标拖拽滚动效果
import Vue from 'vue'
Vue.directive('dragscroll', function (el) {
el.onmousedown = function (ev) {
const disX = ev.clientX
const disY = ev.clientY
const originalScrollLeft = el.scrollLeft
const originalScrollTop = el.scrollTop
const originalScrollBehavior = el.style['scroll-behavior']
const originalPointerEvents = el.style['pointer-events']
el.style['scroll-behavior'] = 'auto'
// 鼠标移动事件是监听的整个document,这样可以使鼠标能够在元素外部移动的时候也能实现拖动
document.onmousemove = function (ev) {
ev.preventDefault()
const distanceX = ev.clientX - disX
const distanceY = ev.clientY - disY
el.scrollTo(originalScrollLeft - distanceX, originalScrollTop - distanceY)
// 由于我们的图片本身有点击效果,所以需要在鼠标拖动的时候将点击事件屏蔽掉
el.style['pointer-events'] = 'none'
}
document.onmouseup = function () {
document.onmousemove = null
document.onmouseup = null
el.style['scroll-behavior'] = originalScrollBehavior
el.style['pointer-events'] = originalPointerEvents
}
}
})
现有库
移动端适配解决方案
历史
一种流行已久的移动端适配方案,那就是rem,我想下面这两句代码,有不少老移动端都不会陌生:
const deviceWidth = document.documentElement.clientWidth || document.body.clientWidth;
document.querySelector('html').style.fontSize = deviceWidth / 7.5 + 'px';
在那个移动端UI稿尺寸为750*1334满天飞的时代,这两句代码确实给开发者带来了很大的方便,这样设置根font-size后,px和rem的转换比例成了100, 为比如UI稿一个长宽分别为120px*40px,那么开发者对应的写成1.2rem*0.4rem就可以了
这种换算已经是颇为方便,但是并非所有的项目都能这样去设置一个方便换算的比例系数,当比例系数为100时,小数点往前面挪两位就行了,然而有的项目设置的换算系数千奇百怪,有50的,有16的,很多已经严重超出口算力所能及的范畴了。所以后来诞生的px-to-rem或者px2rem就是为了解决这个问题
期望
- 首先,无论换算方不方便,我都不想换算(就是这么懒?),我也不想去操心什么转换系数
- 其次,有些属性或者类选择器我不想进行转换
- css代码要足够简洁,我只希望看到一种单位,那就是px
第一种方案
第一种方案是lib-flexible + postcss-pxtorem,在相当长一段时间里,这两个插件搭配都是解决移动端布局的神器,lib-flexible是阿里手淘系开源的一个库,用于设置font-size,同时处理一些窗口缩放的问题。
第二种方案是viewport
postcss-px-to-viewport就是这样一款优秀的插件,它解决了以上提到的痛点,也满足以上提到的理想要求。它将px转换成视口单位vw,众所周知,vw本质上还是一种百分比单位,100vw即等于100%,即window.innerWidth
用法
- npm i postcss-px-to-viewport -D
- 在项目根目录下添加
.postcssrc.js文件 - 添加如下配置:
module.exports = {
plugins: {
autoprefixer: {}, // 用来给不同的浏览器自动添加相应前缀,如-webkit-,-moz-等等
"postcss-px-to-viewport": {
unitToConvert: "px", // 要转化的单位
viewportWidth: 750, // UI设计稿的宽度
unitPrecision: 6, // 转换后的精度,即小数点位数
propList: ["*"], // 指定转换的css属性的单位,*代表全部css属性的单位都进行转换
viewportUnit: "vw", // 指定需要转换成的视窗单位,默认vw
fontViewportUnit: "vw", // 指定字体需要转换成的视窗单位,默认vw
selectorBlackList: ["wrap"], // 指定不转换为视窗单位的类名,
minPixelValue: 1, // 默认值1,小于或等于1px则不进行转换
mediaQuery: true, // 是否在媒体查询的css代码中也进行转换,默认false
replace: true, // 是否转换后直接更换属性值
exclude: [/node_modules/], // 设置忽略文件,用正则做目录名匹配
landscape: false // 是否处理横屏情况
}
}
};
注意
propList: 当有些属性的单位我们不希望转换的时候,可以添加在数组后面,并在前面加上!号,如propList: ["*","!letter-spacing"],这表示:所有css属性的属性的单位都进行转化,除了letter-spacing的selectorBlackList:转换的黑名单,在黑名单里面的我们可以写入字符串,只要类名包含有这个字符串,就不会被匹配。比如selectorBlackList: ['wrap'],它表示形如wrap,my-wrap,wrapper这样的类名的单位,都不会被转换
兼容第三方UI库
开发中可能遇到一下情况,第三方库 是375px的设计稿去做的, 而自己的ui 是按 750 px 设计搞,所以我们要针对不同的 库定义不同的 viewportWidth 尺寸, 看代码
const path = require('path');
module.exports = ({ file }) => {
const designWidth = file.dirname.includes(path.join('node_modules', 'vant')) ? 375 : 750;
return {
plugins: {
autoprefixer: {},
"postcss-px-to-viewport": {
unitToConvert: "px",
viewportWidth: designWidth,
unitPrecision: 6,
propList: ["*"],
viewportUnit: "vw",
fontViewportUnit: "vw",
selectorBlackList: [],
minPixelValue: 1,
mediaQuery: true,
exclude: [],
landscape: false
}
}
}
}
// 注意:这里使用path.join('node_modules', 'vant')是因为适应不同的操作系统,在mac下结果为node_modules/vant,而在windows下结果为node_modules\vant
umi postcss 其他的 一些插件
// 额外的postcss插件用这个extraPostCSSPlugins:
extraPostCSSPlugins: [
postcssImport({}),
postcssUrl({}),
postcssAspectRatioMini({}),
postcssWriteSvg({ utf8: false }),
postcsscssnext({}),
pxToViewPort({
viewportWidth: 720, // (Number) The width of the viewport.
viewportHeight: 1280, // (Number) The height of the viewport.
unitPrecision: 3, // (Number) The decimal numbers to allow the REM units to grow to.
viewportUnit: 'vw', // (String) Expected units.
selectorBlackList: ['.ignore', '.hairlines'], // (Array) The selectors to ignore and leave as px.
minPixelValue: 1, // (Number) Set the minimum pixel value to replace.
mediaQuery: false // (Boolean) Allow px to be converted in media queries.
}),
cssnano({
preset: "advanced",
autoprefixer: false,
"postcss-zindex": false,
zindex: false
})
],
Mac os 做系统u盘
U盘 fat32,硬盘 gpt 分区, UEFI 引导, 方式安装纯净win10
原由:
- mac 格式化只支持 fat32 ,exfat;BIOS 又不支持 exfat 引导
- 1809的64位有个文件挺大的,fat32已经无法写进去了,然后我试过ntfs和exfat,均无法在BIOS里引导启动。一般的 UEFI 固件是不能识别 FAT32 格式以外的格式,除非主板厂商添加了 NTFS 的驱动模块。
- 而你说的那个文件是 install.wim ,Windows 的映像,官方 MediaCreationTool 制作的是 ESD(高压缩) 格式的 install.esd 不会超过 4GB 。
- wimlib-imagex 分割 install.wim
- 需要bios支持uefi同时硬盘使用gpt, 需要用gdisk 命令 转换分区表(而且是无损的哦)
解决方法 windows 系统下
如果你不是使用非常规版本,还是尽量使用 MediaCreationTool 制作 ISO
其实如果愿意花点时间,可以用 dism 把 install.wim 里面的版本映像导出来重新封装成 ESD ,可以做到比官方制作的更小
1.把install.win 制作的是 ESD(高压缩) 格式的 install.esd
DISM /Export-Image /SourceImageFile:X:\install.wim /SourceIndex:1 /DestinationImageFile:Y/install.esd /compress:recovery /CheckIntegrity
2 dism /Split-Image 分割两个文件
Dism /Split-Image /ImageFile:E:\sources\install.wim /SWMFile:D:\images\install.swm /FileSize:2000
方法1: UEFI 方式,win10 文件写入u盘, 支持UEFI+ GPT 引导
diskutil eraseDisk <format> <name> [APM|MBR|GPT] MountPoint|DiskIdentifier|DeviceNode
//格式化优盘
diskutil eraseDisk MS-DOS "WINDOWS10" MBR disk2
// 查看 install 大小
ls -lh /Volumes/CCCOMA_X64FRE_EN-US_DV9/sources/install.wim
// install.wim 小于 4g
rsync -avh --progress /Volumes/CCCOMA_X64FRE_EN-US_DV9/ /Volumes/WINDOWS10
// install.wim 大于 4g 时 先复制其他的
rsync -avh --progress --exclude=sources/install.wim /Volumes/CCCOMA_X64FRE_EN-US_DV9/ /Volumes/WINDOWS10
Download wimlib and use it to split install.wim
// 安装 wimlib
brew install wimlib
//分割 install.wim, 并写入U盘里
wimlib-imagex split /Volumes/CCCOMA_X64FRE_EN-US_DV9/sources/install.wim /Volumes/WINDOWS10/sources/install.swm 3800
方法2: iso镜像写入U盘, 支持MBR 引导
//将U盘unmount(将N替换为挂载路径):
diskutil unmountDisk /dev/disk[N]
//rdisk 中加入r可以让写入速度加快
sudo dd if=/Users/wei/Downloads/Win10_20H2_English_x64.iso of=/dev/rdisk2 bs=1m
gdisk mbr 和 gpt 互相转换
gdisk /dev/sd[x]
MBR to GPT
Enter w to write GPT partition on disk.
Press y to confirm your choice.
GPT to MBR
Enter r to enter in recovery and transformation options.
Enter g to convert GPT to MBR partition.
文件系统与引导关系,参考
物理机-mbr-legacy路径:需要采用mbr分区表的硬盘
#不建议用混合mbr&gpt硬盘,因为不同操作系统的处理方式不一样
*把安装镜像解压到该硬盘ntfs/fat32格式的主分区上
*写入相应mbr和pbr//这里我忘了具体应该写入什么了
*重启选择该硬盘启动
*如果以上过程覆盖了grub的mbr,那么你需要把grub的mbr写回来,并运行一次grub的自动配置脚本,或重新安装grub
物理机-gpt-uefi路径:需要bios支持uefi同时硬盘使用gpt
*把安装镜像解压到fat32分区
*用windows 10的bootmgfw.efi替换镜像中的bootmgfw.efi
*用你喜欢的任何方式让你可以在之后的引导bootmgfw.efi。包括但不限于使用grub的自动配置脚本,修改grub.cfg,使用uefi shell,使用efibootmgr,使用grub的命令行模式。
#个人建议使用uefi shell。
*重启并打开csm
*引导bootmgfw.efi
*完成后,在esp中用grubx64.efi替换bootx64.efi,删除镜像所在分区,并运行grub的自动配置脚本,或重新安装grub
qemu-kvm-gpt-uefi路径:建议双硬盘
#以这种方法安装之后,系统同样可以直接在物理机上启动
*修改镜像,替换bootmgfw.efi(用windows 10的)
*准备硬盘
*将该硬盘初始化为gpt,建立fat32格式的esp,并复制uefi shell
*下载ovmf的bios固件二进制
*准备qemu配置:启用kvm,以ovmf为bios,挂载该硬盘和光盘镜像,从硬盘启动:建议尽可能开启iommu并passthrough硬件。
*以该配置启动qemu并安装
*按照物理机硬件安装驱动程序。有些在此时无法安装的驱动可以在以物理机方式启动后安装。
*关闭qemu,在物理机上为windows建立引导,例如运行grub的自动配置脚本
qemu-kvm-mbr-legacy路径:建议双硬盘
#同上
*准备硬盘
*初始化为mbr
*准备qemu配置:挂载硬盘和镜像,从镜像启动,尽可能passthrough
*完成安装
*安装驱动程序注:qemu可以挂载你linux所在的硬盘,但是这可能导致你linux所在硬盘的损坏,并且安装完成后你需要重新安装/修复grub