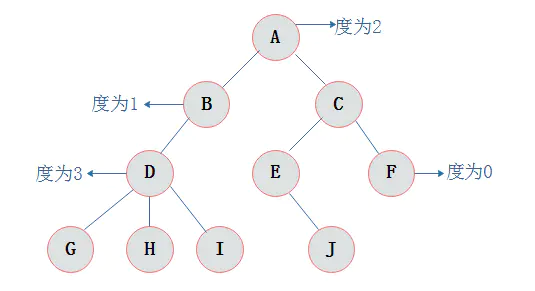
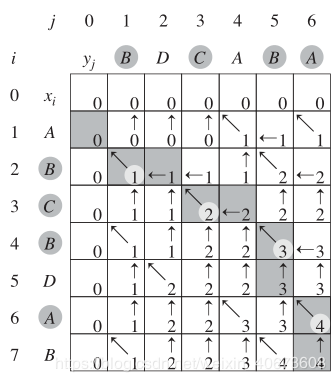
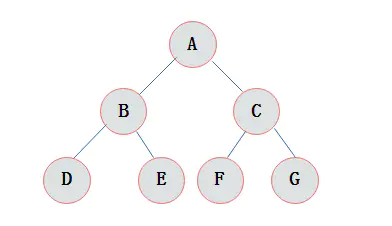
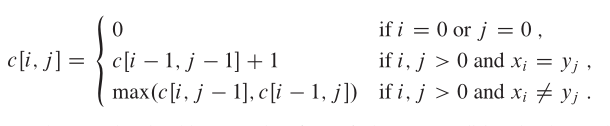库存列表:skuList,规格列表:skuNameList,属性:skuNameList-skuValues数组下的单个元素,规格:skuNameList下的单个元素
// 库存列表
const skuList = [
{
skuId: '0',
skuGroup: ['红色', '大'],
remainStock: 7,
price: 2,
picUrl: 'https://dummyimage.com/100x100/ff00b4/ffffff&text=大'
},
{
skuId: '1',
skuGroup: ['红色', '小'],
remainStock: 3,
price: 4,
picUrl: 'https://dummyimage.com/100x100/ff00b4/ffffff&text=小'
},
{
skuId: '2',
skuGroup: ['蓝色', '大'],
remainStock: 0,
price: 0.01,
picUrl: 'https://dummyimage.com/100x100/0084ff/ffffff&text=大'
},
{
skuId: '3',
skuGroup: ['蓝色', '小'],
remainStock: 1,
price: 1,
picUrl: 'https://dummyimage.com/100x100/0084ff/ffffff&text=小'
}
];
// 规格列表
const skuNameList = [
{
skuName: "颜色",
skuValues: ["红色", "蓝色"]
},
{
skuName: "尺寸",
skuValues: ["大", "小"]
}
];
将规格列表下的已选属性集合作为入参 selected,如果在当前规格未选择相关属性则传入空字符串,即最开始时 selected === [”, ”]
/**
* 获取sku信息
* @param {Array} selected 已选属性数组
* @return {Object} skuInfo
*/
function getSkuinfo (selected){
// 用以记录每个按钮状态的,例如 itemState['红色'] = true 表示高亮
const attrState = {};
let picUrl = '';
let minPrice = Number.MAX_VALUE;
let maxPrice = 0;
let remainStock = 0;
// in array not in others
const difference = (array, others) => {
return array.filter((item) => others.indexOf(item) === -1);
};
// every in array in others return true or false
const isSubset = (array, others) => {
return array.every((item) => others.indexOf(item) > -1);
};
skuNameList.foreach(spec => {
//selected 中有 在 spec.skuValues 里的先删除
var temp = difference(selected, spec.skuValues)
skuValues.foreach(name => { // 遍历规格
// 再加上 这一行的一个规格, 其他行已选和本行规格的组合就出来了
// 如果组合属于 库存中某个skuGroup的子集 说明这个 规格可选
var combinedTemp = [...temp, name];
attrState[name] = false; // 先设为false
for(var i = 0; i < skuList.length; i++){
var skuGroup = skuList[i].skuGroup
if(isSubset(combinedTemp, skuGroup)&& skuList[i].remainStock)
{
attrState[name] = true;
break; // 如果其中有一个库存, 这个属性就可以选,然后退出循环
}
}
})
})
// 实际已选属性,过滤空字符串
const realSelected = selected.filter((item) => item);
const defaultSelected = selected.map(
(name, idx) => name || skuNameList[idx].skuValues[0]
);
skuList.forEach(sku => {
if(isSubset(selected,sku.skuGroup)){
remainStock += sku.remainStock;
minPrice = Math.min(minPrice, sku.price);
maxPrice = Math.max(maxPrice, sku.price);
// 取当前图片
if (isSubset(defaultSelected, sku.skuGroup)) {
picUrl = sku.picUrl;
}
}
})
return {
attrState,
picUrl,
minPrice,
maxPrice,
remainStock,
};
}