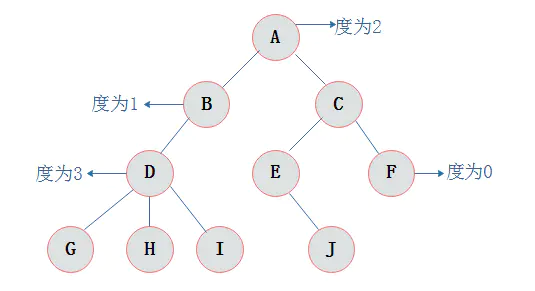
树
度:一个节点有几个分支就是几度
层:根为第一层,根的孩子为第二层,以此类推
深度:最大层次数为树的深度
二叉树
二叉树特点
由二叉树定义以及图示分析得出二叉树有以下特点:
1)每个结点最多有两颗子树,所以二叉树中不存在度大于2的结点。
2)左子树和右子树是有顺序的,次序不能任意颠倒。
3)即使树中某结点只有一棵子树,也要区分它是左子树还是右子树。
二叉树性质
1)在二叉树的第i层上最多有2�^(i-1) 个节点 。(i>=1)
2)二叉树中如果深度为k,那么最多有2^k-1个节点。(k>=1)
3)n0=n2+1 n0表示度数为0的节点数,n2表示度数为2的节点数。
4)在完全二叉树中,具有n个节点的完全二叉树的深度为[log2^n]+1,其中[log2n]是向下取整。
5)若对含 n 个结点的完全二叉树从上到下且从左至右进行 1 至 n 的编号,则对完全二叉树中任意一个编号为 i 的结点有如下特性:
(1) 若 i=1,则该结点是二叉树的根,无双亲, 否则,编号为 [i/2] 的结点为其双亲结点;
(2) 若 2i>n,则该结点无左孩子, 否则,编号为 2i 的结点为其左孩子结点;
(3) 若 2i+1>n,则该结点无右孩子结点, 否则,编号为2i+1 的结点为其右孩子结点。
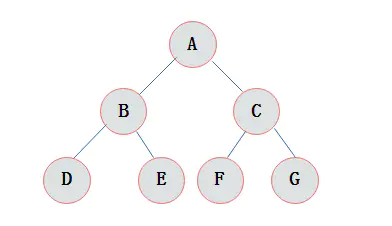
3.5 满二叉树
满二叉树:在一棵二叉树中。如果所有分支结点都存在左子树和右子树,并且所有叶子都在同一层上,这样的二叉树称为满二叉树。
满二叉树的特点有:
1)叶子只能出现在最下一层。出现在其它层就不可能达成平衡。
2)非叶子结点的度一定是2。
3)在同样深度的二叉树中,满二叉树的结点个数最多,叶子数最多。
 满二叉树
满二叉树
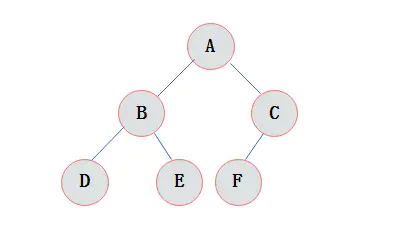
3.6 完全二叉树
完全二叉树:对一颗具有n个结点的二叉树按层编号,如果编号为i(1<=i<=n)的结点与同样深度的满二叉树中编号为i的结点在二叉树中位置完全相同,则这棵二叉树称为完全二叉树。
特点:
1)叶子结点只能出现在最下层和次下层。
2)最下层的叶子结点集中在树的左部。
3)倒数第二层若存在叶子结点,一定在右部连续位置。
4)如果结点度为1,则该结点只有左孩子,即没有右子树。
5)同样结点数目的二叉树,完全二叉树深度最小。
注:满二叉树一定是完全二叉树,但反过来不一定成立。
3.7 二叉树的存储结构
二叉树的顺序存储结构就是使用一维数组存储二叉树中的结点,并且结点的存储位置,就是数组的下标索引。
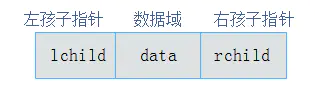
3.7.2 二叉链表
既然顺序存储不能满足二叉树的存储需求,那么考虑采用链式存储。由二叉树定义可知,二叉树的每个结点最多有两个孩子。因此,可以将结点数据结构定义为一个数据和两个指针域。表示方式如图3.11所示:
3.8 二叉树遍历
二叉树的遍历是指从二叉树的根结点出发,按照某种次序依次访问二叉树中的所有结点,使得每个结点被访问一次,且仅被访问一次。
二叉树的访问次序可以分为四种
前序遍历
中序遍历
后序遍历
层序遍历
前序遍历通俗的说就是从二叉树的根结点出发,当第一次到达结点时就输出结点数据,按照先向左在向右的方向访问。
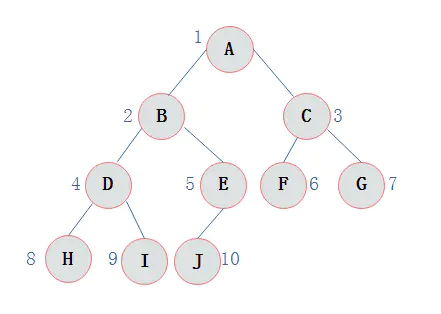
从根结点出发,则第一次到达结点A,故输出A;
继续向左访问,第一次访问结点B,故输出B;
按照同样规则,输出D,输出H;
当到达叶子结点H,返回到D,此时已经是第二次到达D,故不在输出D,进而向D右子树访问,D右子树不为空,则访问至I,第一次到达I,则输出I;
I为叶子结点,则返回到D,D左右子树已经访问完毕,则返回到B,进而到B右子树,第一次到达E,故输出E;向E左子树,故输出J;按照同样的访问规则,继续输出C、F、G; 则3.13所示二叉树的前序遍历输出为: ABDHIEJCFG
3.8.3 中序遍历
中序遍历就是从二叉树的根结点出发,当第二次到达结点时就输出结点数据,按照先向左在向右的方向访问。
二叉树中序访问如下: 从根结点出发,则第一次到达结点A,不输出A,继续向左访问,第一次访问结点B,不输出B;继续到达D,H;到达H,H左子树为空,则返回到H,此时第二次访问H,故输出H;
H右子树为空,则返回至D,此时第二次到达D,故输出D;
由D返回至B,第二次到达B,故输出B;
按照同样规则继续访问,输出J、E、A、F、C、G;
则3.13所示二叉树的中序遍历输出为:
HDIBJEAFCG
3.8.4 后序遍历
后序遍历就是从二叉树的根结点出发,当第三次到达结点时就输出结点数据,按照先向左在向右的方向访问。
二叉树后序访问如下:
从根结点出发,则第一次到达结点A,不输出A,继续向左访问,第一次访问结点B,不输出B;继续到达D,H;
到达H,H左子树为空,则返回到H,此时第二次访问H,不输出H;
H右子树为空,则返回至H,此时第三次到达H,故输出H;
由H返回至D,第二次到达D,不输出D;
继续访问至I,I左右子树均为空,故第三次访问I时,输出I;
返回至D,此时第三次到达D,故输出D;
按照同样规则继续访问,输出J、E、B、F、G、C,A;
则图3.13所示二叉树的后序遍历输出为:
HIDJEBFGCA
function TreeCode() {
let BiTree = function (ele) {
this.data = ele;
this.lChild = null;
this.rChild = null;
}
this.createTree = function () {
let biTree = new BiTree('A');
biTree.lChild = new BiTree('B');
biTree.rChild = new BiTree('C');
biTree.lChild.lChild = new BiTree('D');
biTree.lChild.lChild.lChild = new BiTree('G');
biTree.lChild.lChild.rChild = new BiTree('H');
biTree.rChild.lChild = new BiTree('E');
biTree.rChild.rChild = new BiTree('F');
biTree.rChild.lChild.rChild = new BiTree('I');
return biTree;
}
}
//前序遍历
function ProOrderTraverse(biTree) {
if (biTree == null) return;
console.log(biTree.data);
ProOrderTraverse(biTree.lChild);
ProOrderTraverse(biTree.rChild);
}
//中序遍历
function InOrderTraverse(biTree) {
if (biTree == null) return;
InOrderTraverse(biTree.lChild);
console.log(biTree.data);
InOrderTraverse(biTree.rChild);
}
//后续遍历
function PostOrderTraverse(biTree) {
if (biTree == null) return;
PostOrderTraverse(biTree.lChild);
PostOrderTraverse(biTree.rChild);
console.log(biTree.data);
}
let myTree = new TreeCode();
console.log(myTree.createTree());
console.log('前序遍历')
ProOrderTraverse(myTree.createTree());
console.log('中序遍历')
InOrderTraverse(myTree.createTree());
console.log('后续遍历')
PostOrderTraverse(myTree.createTree());
二叉树的按层遍历法
二叉树分好多层,因为要按层遍历,所以如果直接采用函数递归的话,一下子就深入层底了,达不到按层的目的。
所以要换一个角度,按照队列顺序输出!算法步骤如下:
1、把根节点A放入队列,此时队列为:A,队列头指针指向A,也就是队列第一个元素
2、把当前队列头指针所指元素的左右儿子放入队列,即将B C放入队列,此时队列为A B C ,队列头指针向下移一格,此时指向B
3、不断重复2步骤。此时把B的左右儿子取出来放入队尾,队列变为A B C D E,队列头指针后移,指向c,c没有子节点,队列不再延长;
4、结束条件,队列头指针和为指针重合时,输出最后一个元素,算法结束!
也就是说,把这个队列从头到尾输出一遍,就是按层遍历,这个队列是动态的,只要有子节点,子节点就会不停的加入队尾,但总有子节点没有的时候,所以,队列尾指针肯定有不再移动的时候,而头指针一直在一步一步向下移,总会有首尾指针重合的时候,即标志着算法结束。
void Layer_order(BiTree * TNode,BiTree ** F,BiTree ** R)
{
*F=TNode; //将当前节点放入队列首指针所指位置
printf("%c ",(*F)->data);
if((*F)->lchild!=NULL) {
R=R+1;
*R=(*F)->lchild; //节点的左儿子放入队尾
}
if((*F)->rchild!=NULL){
R=R+1; //首指针向后移动一格
*R=(*F)->rchild; //节点的右儿子放入队尾
}
if(F!=R){
F=F+1;
Layer_order(*F,F,R);//递归
}
}
4、写main函数,建立一个队列,长度1024,存放节点指针(其实就是一个存放指针的数组),这一部分放在main函数中,这个队列是唯一的,不参与递归
BiTree ** F; //队首指针 指向指针的指针,因为队列数组里的元素全是指针
BiTree ** R; //队尾指针
BiTree * Queue[1024];//队列数组
F=Queue;
R=Queue; //开始时队首队尾指针重合
BiTree * root; //在main函数中建立一个二叉树根的指针
root=CreatBiTree(); //创建树
Layer_order(root,F,R); //按层遍历树


